문제 링크
https://leetcode.com/problems/merge-k-sorted-lists/
나의 풀이
첫 번째 시도 (시간 초과)
- 매 루프마다 각 연결 리스트의 head value를 리스트로 저장하고, 최솟값에 해당하는 연결 리스트의 값을
result에 저장 후 갱신하는 방법을 사용했다. - 결과는 이상이 없지만 시간 초과로 인하여 오답 처리가 되었다.
소스 코드
from typing import List
class Solution:
def my_solution1(self, lists: List[ListNode]) -> ListNode:
if not lists:
return None
result = merged = ListNode(None)
while 1:
curr = [node.val if node else float('inf') for node in lists]
min_value = min(curr)
if min_value != float('inf'):
idx = curr.index(min_value)
merged.next = ListNode(lists[idx].val)
merged = merged.next
lists[idx] = lists[idx].next
else:
break
return result.next
두 번째 시도
- 매 루프마다 각 연결 리스트의 head value를 리스트로 저장하는 방법 대신 루프 이전에 미리 리스트를 생성해놓고, 최솟값을 찾으면 해당 인덱스의 값을 변경하는 방법을 사용했다.
- 무사히 통과는 했으나, 여전히 느리다.
소스 코드
from typing import List
class Solution:
def my_solution2(self, lists: List[ListNode]) -> ListNode:
if not lists:
return None
result = merged = ListNode(None)
curr = [[node.val, i] if node else (float('inf'), i) for i, node in enumerate(lists)]
while 1:
min_value, min_idx = min(curr, key=lambda x: x[0])
if min_value != float('inf'):
merged.next = ListNode(lists[min_idx].val)
merged = merged.next
lists[min_idx] = lists[min_idx].next
curr[min_idx][0] = lists[min_idx].val if lists[min_idx] else float('inf')
else:
break
return result.next
문제 풀이
우선순위 큐를 이용한 리스트 병합
heapq모듈(최소 힙)을 사용하여 간단하게 해결할 수 있음
소스 코드
from typing import List
import heapq
class solution:
def solution1(self, lists: List[ListNode]) -> ListNode:
root = result = ListNode(None)
heap = []
# 각 연결 리스트의 루트를 힙에 저장
for i in range(len(lists)):
if lists[i]:
# heapq에는 중복된 값을 저장할 수 없기 때문에
# 중복된 값을 구분할 수 있도록 다음과 같이 3개의 값을 튜플로 묶어 인자로 전달
heapq.heappush(heap, (lists[i].val, i, lists[i]))
# 힙 추출 이후 다음 노드는 다시 저장
while heap:
node = heapq.heappop(heap)
idx = node[1]
result.next = node[2]
result = result.next
if result.next:
heapq.heappush(heap, (result.next.val, idx, result.next))
return root.next
heapq모듈을 사용하여 문제를 푼 결과 압도적인 실행 시간 차이를 보여준다.
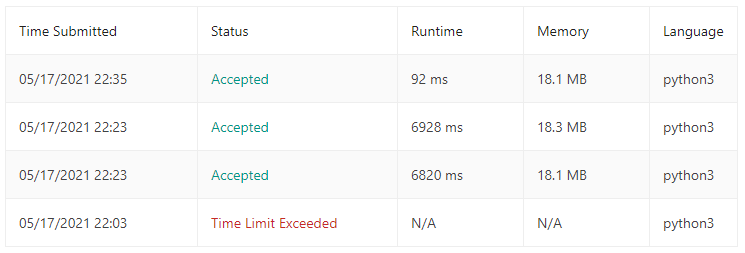
배운 점
파이썬에서의 우선순위 큐
- 파이썬에서 우선순위 큐는
heapq모듈과queue.PriorityQueue클래스를 이용해 사용할 수 있지만, 후자는 내부적으로heapq를 사용하도록 구현되어 있기 때문에 사실상 둘은 동일하다. - 차이점이 있다면 전자는 후자에 비해 멀티 스레드 환경에서 안전하지 않다. 즉, 스레드 세이프(Thread-Safe)를 보장하지 않는다.
- 하지만 파이썬은 GIL의 특성상 멀티 스레딩이 거의 의미가 없으므로
PriorityQueue의 멀티 스레딩 지원은 그리 큰 의미를 가지지 않는다. 그리고 스레드 세이프를 보장한다는 건 성능에 영향을 끼친다는 뜻이기도 하다. (내부적으로 락킹(Locking)을 제공하며, 락킹 오버헤드(Locking Overhead)가 발생하므로)- GIL(Global Interpreter Lock, 전역 인터프리터 락): 하나의 스레드가 자원을 독점하는 형태로 실행
- CPython 개발 초기에 번거로운 동시성 관리를 편리하게 하고, 스레드 세이프하지 않은 CPython의 메모리 관리를 쉽게 하기 위해 도입했으나, 멀티 코어가 당연한 지금은 치명적인 특징이다.
- GIL(Global Interpreter Lock, 전역 인터프리터 락): 하나의 스레드가 자원을 독점하는 형태로 실행
- 실무에서도 우선순위 큐는 대부분
heapq로 구현한다고 하니, 그냥 웬만하면heapq를 쓰는 게 낫다.